Minimal hyperconverged kubernetes cluster
Posted on za 05 augustus 2023 in kubernetes
While I've been using kubernetes for years now, I never dived into building my own cluster. I was always focused on delivering value on top of that via the kubernetes API. I just wanted to work with that API and not worry about the underlying infra. For real deployments I used managed kubernetes somewhere by someone or I used k3s on a single node when that was sufficient.
I have yet to find someone who does managed multi node kubernetes hosting for development work. There are lots of choices to get managed k8s, but they al seem targeted at actual production use with uptimes guarantees and high costs. And yet I came to more situations where I wanted something really production like beyond the single node setup, without the actual uptime guarantees and costs.
First I looked at a very nice tool called hetzner-k3s. This will very quickly and easily deploy a multi node k3s cluster for you, being somewhat opinionated leaving you with a small cluster to use. I tried a couple of deployments, but as it is now, it only delivers RWO (ReadWriteOnce) volumes, while ideally I would be able to use RWX (ReadWriteMany) volumes too. You could of course deploy something on top to fake this, but that would make it quite fragile.
I considered using CEPH multiple times, but just running CEPH for development/pet projects seemed complicated, expensive and somewhat overkill.
Then I thought, is it not possible to do something 'hyperconverged' where you combine memory, compute and storage on the same machines. hyperconverged is more of a virtual machine management idea, but I figured I might be able to apply it to a small kubernetes setup. Then I remembered a thing called 'gluster', a distributed storage solution I had never used and only heard coworkers talk about in the past.
So that is what I ended up doing. Building a three node setup, where all the nodes are running k8s/kubernetes and gluster. It took a couple of deployments to get to the setup I have now. There is still some manual labour needed to make it all work, but I think it is good enough now for. Over the next months I will deploy/run some services on top of this cluster to get a feel how stable a solution this is.
Schematic
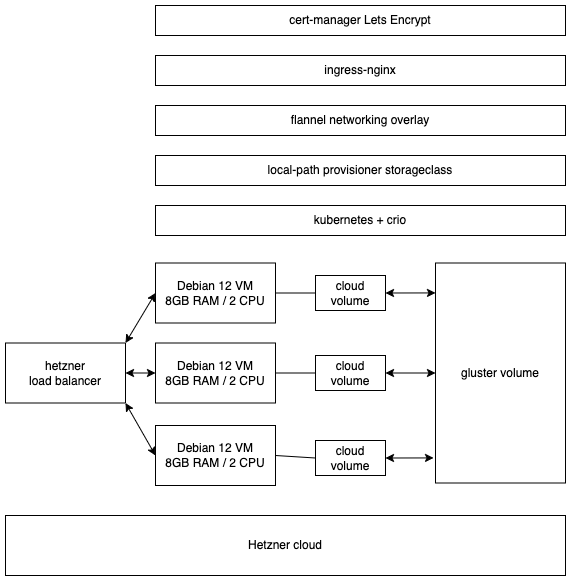
Building blocks
Right now 90% is automated and reproducable. Only when the setup proves reliable over time, will I spent the time needed to completely automate the whole deployment process
- terraform code to deploy virtual machines, volumes, the load balancer and DNS entries
- hook to kick of ansible code
- ansible code to deploy gluster and kubernetes packages, plus my own baseline for secure enough defaults to run on the public Internet
- ansible playbook to setup gluster and a shared volume on all three nodes
- automatic init of first cluster node with kubeadm
- hosts: config_init
tasks:
- name: "Add gluster node {{ groups['clusternodes'][1] }}"
shell: "gluster peer probe {{ groups['clusternodes'][1] }}"
tags: ['never', 'config_init']
- name: 'small pause'
ansible.builtin.pause:
seconds: 5
tags: ['never', 'config_init']
- name: "Add gluster node {{ groups['clusternodes'][3] }}"
shell: "gluster peer probe {{ groups['clusternodes'][2] }}"
tags: ['never', 'config_init']
- name: 'small pause'
ansible.builtin.pause:
seconds: 5
tags: ['never', 'config_init']
- name: "Create gluster volume"
shell: "gluster volume create gvol1 replica 3 {{ groups['clusternodes'][0] }}:/data/brick {{ groups['clusternodes'][1] }}:/data/brick {{ groups['clusternodes'][2] }}:/data/brick"
tags: ['never', 'config_init']
- name: "start gluster volume"
shell: "gluster volume start gvol1"
tags: ['never', 'config_init']
- name: "init the kubernetes cluster on this node"
shell: "kubeadm init --pod-network-cidr=10.244.0.0/16 --control-plane-endpoint {{ cluster_name }}.lutra-cloud.eu --upload-certs >> /root/kubeadm_init.txt"
tags: ['never', 'config_init']
At this point, automation stops I a need to copy/paste stuff from my own README. This will result in a three node kubernetes cluster, with a shared gluster volume that has three replicas for all the files stored in it. So every file stored in the gluster volume is directly available on all three nodes.
Deployed basic services
taint control plane in poor mans version of cluster
First the control plane nodes need to be allowed to run pods, in a real cluster these first three nodes would only do control plane tasks. This is a real concern with multi tenancy. I considered making it a six node thing, with three minimal control plane nodes and three worker nodes. If I ever want something 'proper' on this setup, this will be the first thing to be addressed.
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
local-path provisioner
A service that I took from my previous k3s setups. This will just map a local directory on the kubernetes node to a volume in a pod. For this setup it maps to the gluster volume mountpoint. Also it is configured as a shared volume, making ReadWriteMany a reality:
kind: ConfigMap
apiVersion: v1
metadata:
name: local-path-config
namespace: local-path-storage
data:
config.json: |-
{
"sharedFileSystemPath": "/gvol1"
}
One thing I needed to adjust is that volumes have a reclaim policy of 'Delete' by default. So after deploying a new workload, I need to patch the resource so volumes are not deleted when the pod is deleted:
kubectl patch pv [volumename] -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'
I tried modifying the default policy, but it complained about constraints. Future Me will look into that.
ingress-nginx
(not to be confused with nginx-ingress by Nginx the company)
This mostly just works, but it expects a loadbalancer handler to expose the endpoint. This could have been a hetzner solution, but I wanted to keep bindings to the hetzner to a minimum, so I patched the resource by hand for now, adding the real virtual machines as endpoints:
kubectl patch svc ingress-nginx-controller -p '{"spec": {"type": "LoadBalancer", "externalIPs":["128.145.XX.XX", "167.235.XX.XX", "49.12.XX.XX"]}}'
I still chose to add a hetzner load balancer, but that could easible be replaced with an haproxy setup with little effort.
Future work
First, this setup needs to handle some real world workloads, so that I can learn if this at all a feasible setup in terms of reliability and practical use. If that turns out somewhere between OK and GREAT, I will finish the automation work to cover 99,9%.
Also, I will need to learn more about the actual security issues when running an combined controlplane/worker node.